Learning Chinese (well enough to order from the menu) using MTurk
Wednesday, 19 July 2023
TL;DR: I used MTurk and PostgreSQL to create vocab flash cards for Chinese restaurant menus, ranked from most common to least common terms.
It’s an embarrassing scenario: you’re dining with friends at a Chinese restaurant when the server drops off the menus, including the non-English “secret menu”. All eyes turn to you, as the only Chinese person in the group. “You’re Chinese right? Can you read this?”
I’ve created a tool to solve this problem: a deck of 1,214 flash cards featuring vocabulary found on Chinese menus. The cards are ordered from most common (鸡: chicken) to least common, so if you study them in order, you’ll quickly learn the characters and phrases you’re most likely to encounter.

To do this, I compiled a set of photos of Chinese restaurant menus from places like restaurant websites and Yelp. What I needed was to extract all of the Chinese text but the images weren’t good enough for OCR. Different fonts, complex layouts, and low-quality phone photos of menus (with glare, perspective skew, etc.) made it impossible for OCR to process the text reliably. And even if OCR could get it 90% right, the transcription errors would pollute the data, potentially resulting in some nonsensical datasets.
Thus, MTurk. Using human transcribers, I was able to get all images transcribed with minimal effort on my part. I had to:
- Upload the images somewhere
- Create a set of MTurk tasks, one for each image
- Write a clear description of what I wanted workers to do
- Pay money!
- Download and spot-check results
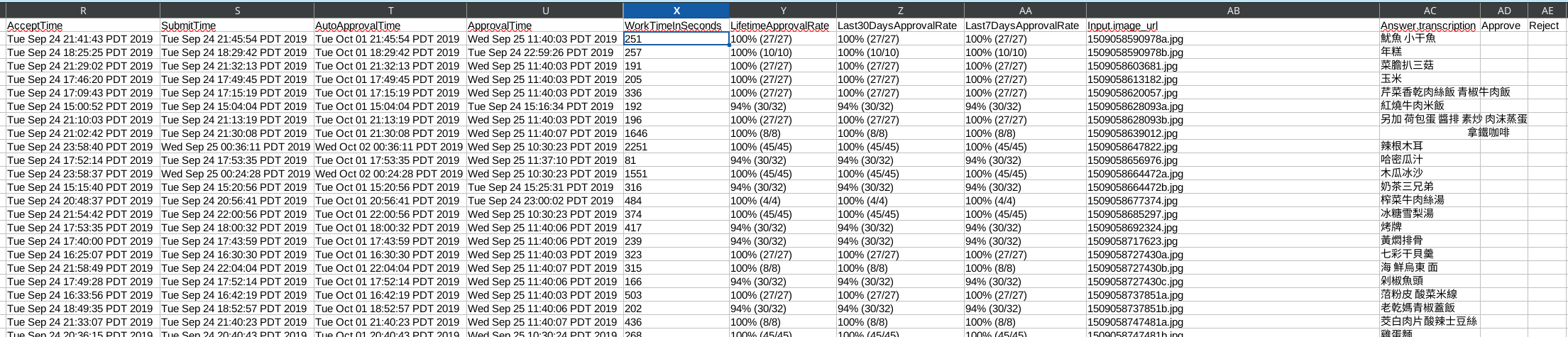
Ultimately I paid $26.40 to get the set of about 150 images transcribed. There was some overhead in approving or rejecting the work – despite making the instructions as clear as I could, some workers transcribed only the English text, or entered gibberish.
![Message from [redacted]
---------------------------------
Worker ID: A9BQD3BA0KKTX
HIT Title: 抄寫餐館菜單
HIT Description: 輸入菜單漢字
HIT ID: 35A1YQPVFEH3FRYTKHQ5HYRFMXSI5J
gibberish you are
---------------------------------
Greetings from Amazon Mechanical Turk,
The message above was sent by an Amazon Mechanical Turk user.
Please review the message and respond to it as you see fit.
Sincerely,
Amazon Mechanical Turk
https://requester.mturk.com](https://notes.ericjiang.com/wp-content/uploads/2023/07/mturk-user-redacted.png)
The next step was to dump everything into a PostgreSQL database to make manipulating the data a bit easier. Using psql’s \copy command also made it easier to ad-hoc reformat the data I needed into CSVs.
From there, I used tools I previously wrote to count characters and multi-character words, creating a list of vocab along with the number of occurrences. The code also grabs definitions from the free CC-CEDICT (available under CC-BY-SA), resulting in a set of “notes” that can be imported by Anki.
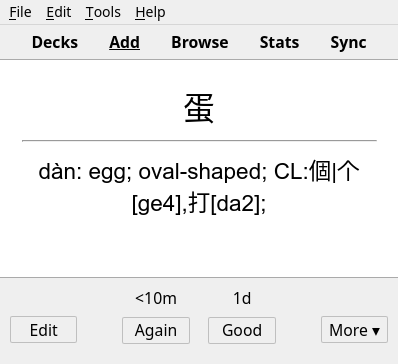
Admittedly the data set could be expanded. With the source data set that I collected, a lot of words only show up once. Words like 巴西 (Brazil), 生姜 (raw ginger), 七喜 (7-Up) are all mixed up in the bottom of the vocab barrel. Such is language learning…
Learning the top 131 cards is enough to recognize 50% of the words in the source menus, and 451 achieves 75% recognition. However, 925 cards are needed for 90% recognition. These numbers are actually worse than reality, as simplified and traditional variants are separate cards, and you will also have learned the constituent characters of many multi-character words. For example, 魚香 is card #39, but 魚 is #19 and 香 is #26.
If you’re interested, have a go at it! The deck of flash cards is available for Anki – all you need to do is import the deck and set aside a few minutes each day to study cards.
Download
To download the vocab list or Anki flash cards, see the Github repository: https://github.com/erjiang/chinesemenus (look under Releases for the APKG Anki deck).