Disclaimer: I am employed by the maker of ChatGPT, although I do not work on Codex.
One way to use ChatGPT Codex is via its CLI program, which is supposed to be for writing code. But more importantly, it can run commands (that you manually approve) on your actual machine! And that means it can be your personal tech support!
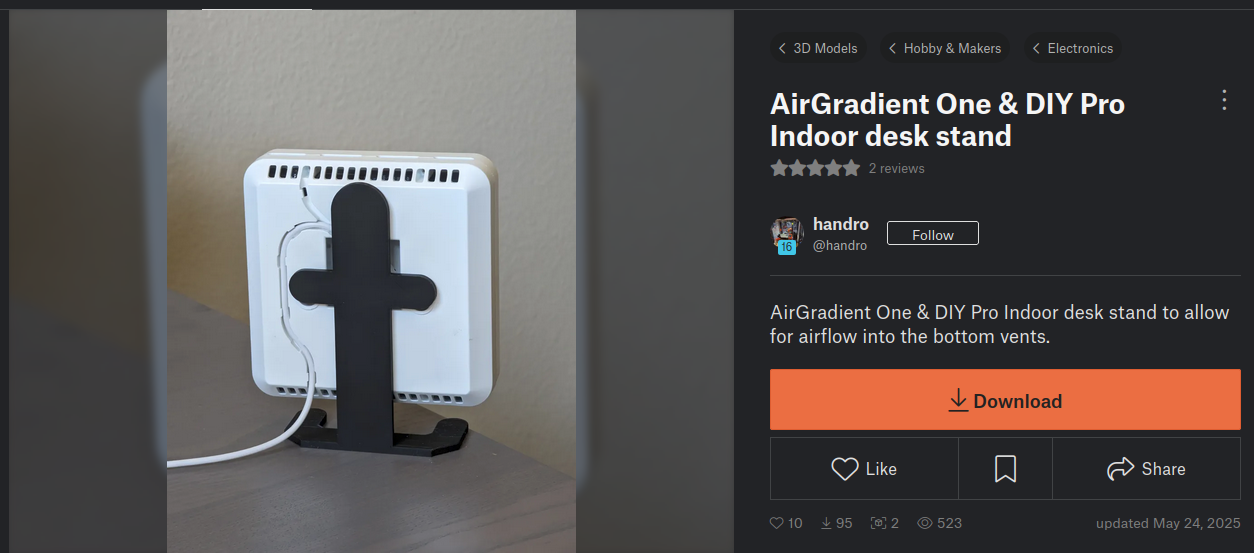
I need this because my personal computer is a desktop running Ubuntu. The OS install has been upgraded many times over the years and has accumulated a decent amount of customization and personal hacks. And my own risky meddling has caused a decent number of problems and weird behavior.
Since Codex can execute commands on your system, it can do things like see your kernel version, read config files, list your PCI devices, and whatever else you would normally try on the CLI. The first time I needed it, I had just done a big upgrade of all the packages on my system and GPU acceleration was no longer working. I did have the Nvidia driver installed, but nvidia-smi didn’t show me my GPUs and programs like Blender complained that I didn’t have any CUDA or OptiX-capable devices.
I simply told Codex, “Figure out why nvidia-smi is not showing my graphics card”, and it:
TL;DR: It’s easy to write an application launcher fit for your exact needs. You can take my hacky code on Github as a starting point.
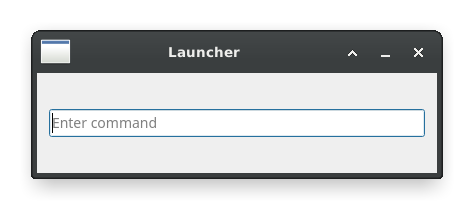
The application launcher (Alt+F2 or Meta+R) is the program I run the most on my desktop because it’s the entry point for most everything else I want to run. A while back, I switched from XFCE to KDE too see what things were like having not used KDE since pre-Plasma. I was shocked by the latency in nearly everything: lag to launch system settings, lag to launch even the application launcher (krunner)! Having to wait 400ms after hitting Meta+R before I can start typing is inexcusable for something that should be very simple. I don’t need a fancy start menu that lists my favorite programs. I don’t need it to search over the contents of my files. There are really only a few things that I need it to do:
Launch a program by name or path
Open a directory
Do basic arithmetic
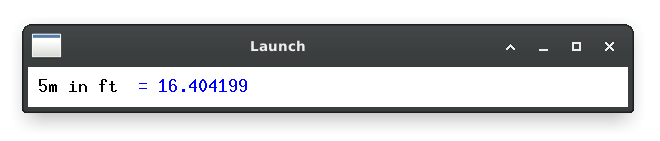
Do basic unit conversions
Your list of necessary launcher tasks is probably different! I looked around a bit and didn’t find something that had this exact feature set, although some certainly could do everything on this list and a lot more. Krunner, for example, has a plug-in system to do things like dictionary lookups, stock price lookup, etc.
Was krunner slow because, in the spirit of KDE, has lots of settings and extensibility? I decided to try writing my own.
My first attempt was to use PyQt5:
Very simple, import PyQt5 and display a window with a text input. About 45 lines of code total. Yet, it still took approximately 150ms to start (as measured from the top of the script until the end of the GUI’s __init__ function). My computer is not slow – this should launch much faster than that, especially on subsequent runs when any code is cached in memory.
Was it because of some costly Python initialization or something? Using some GPT-4o help, I rewrote this Python program in C++ with Qt. Surprisingly, the C++ version was no faster, clocking in at around 140ms. So Qt itself seemed to be the culprit here.
After some back and forth with ChatGPT, it suggested writing the launcher to use X11 calls directly. While doing this would work around needing a heavy UI toolkit, there are unfortunately some downsides. I won’t get any kind of text editing or interactive features – any text I want to display needs to be drawn by my code and there is no built-in support for anything like keyboard shortcuts, text selection, i18n, nice fonts, etc.
Still, why not try it? I’ve never written code for X11, so I asked the AI for some starter code to hit X11 directly and hacked on it a bit:
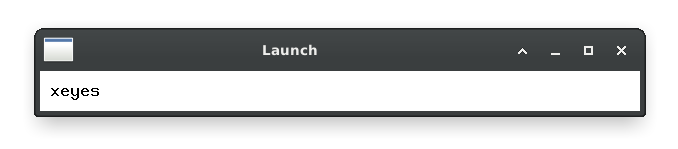
It’s extremely barebones, with not even a blinking text cursor, but the speed is undeniable: 1-2ms to launch. Anything reacting in under 70ms appears to be instantaneous to most users, and this thing basically appears as soon as my keyboard key bottoms out.
On top of this, I added a bunch of code to do simple arithmetic and unit conversion (via units).
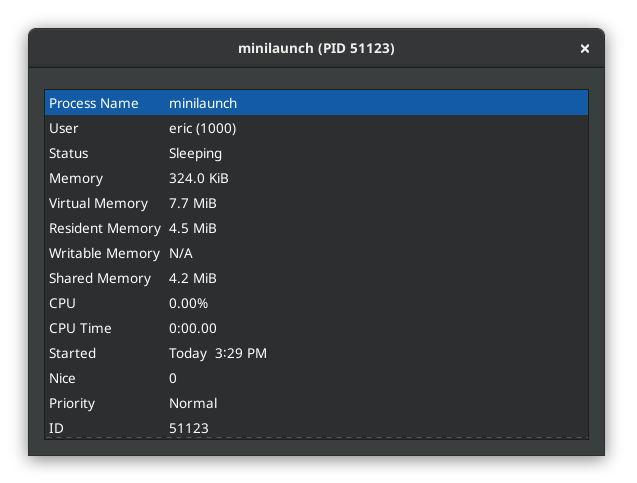
It must be more memory efficient as well, but by how much? gnome-system-monitor says it takes 324 KiB of memory, and the binary itself is about 101 KB. For comparison, krunner sits at about 33 MiB when it’s in the background (although some of that is probably shared KDE libs). My launcher doesn’t need to be backgrounded because there’s no noticeable first-launch penalty.
To be clear, the memory usage is not a concern on a machine with 64 GB of RAM, but you can’t spend your way around laggy software. Unless you write code with latency in mind, it’s easy to add in a few dozen ms of time here and there until you end up with an unpleasant user experience that turns users away.
TL;DR: I used MTurk and PostgreSQL to create vocab flash cards for Chinese restaurant menus, ranked from most common to least common terms.
It’s an embarrassing scenario: you’re dining with friends at a Chinese restaurant when the server drops off the menus, including the non-English “secret menu”. All eyes turn to you, as the only Chinese person in the group. “You’re Chinese right? Can you read this?”
I’ve created a tool to solve this problem: a deck of 1,214 flash cards featuring vocabulary found on Chinese menus. The cards are ordered from most common (鸡: chicken) to least common, so if you study them in order, you’ll quickly learn the characters and phrases you’re most likely to encounter.
To do this, I compiled a set of photos of Chinese restaurant menus from places like restaurant websites and Yelp. What I needed was to extract all of the Chinese text but the images weren’t good enough for OCR. Different fonts, complex layouts, and low-quality phone photos of menus (with glare, perspective skew, etc.) made it impossible for OCR to process the text reliably. And even if OCR could get it 90% right, the transcription errors would pollute the data, potentially resulting in some nonsensical datasets.
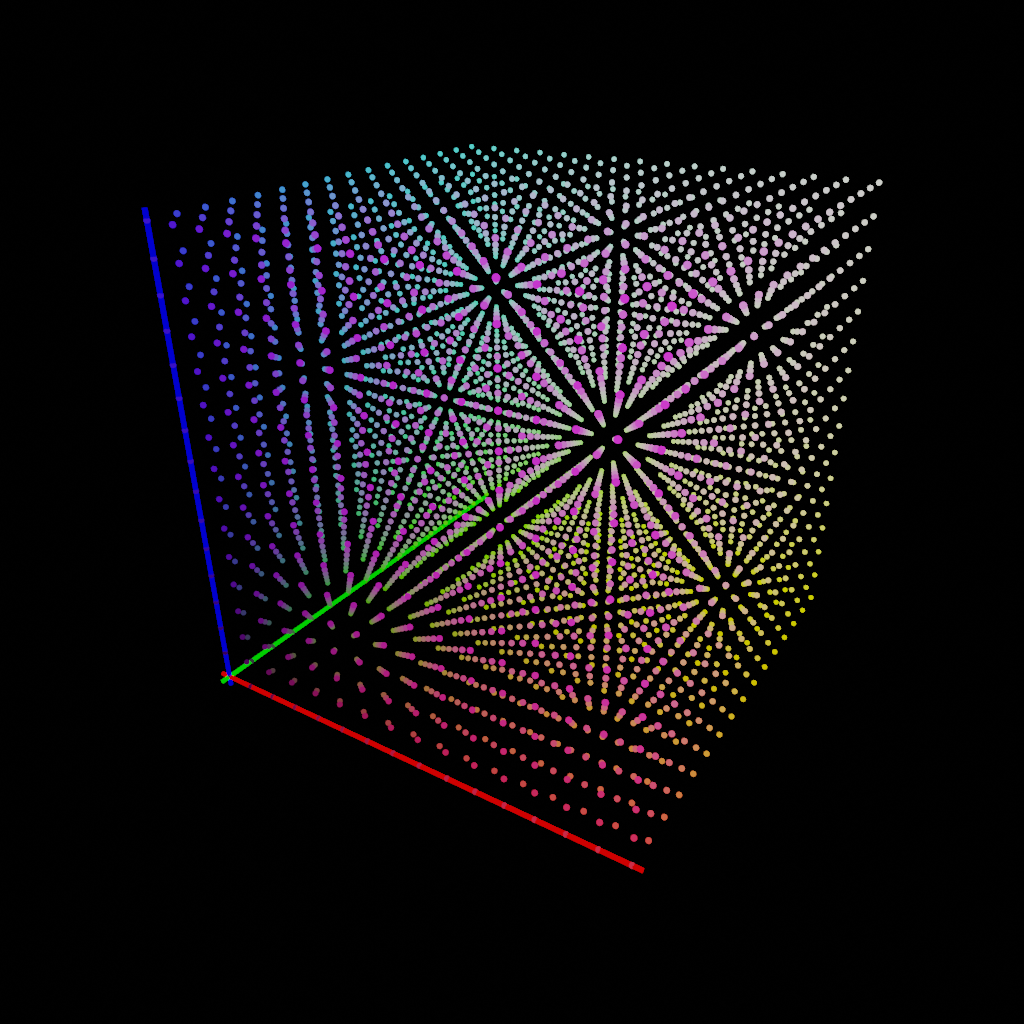
A Look-Up Table, as the name describes, is simply a large table of numbers. Given an input color RᵢGᵢBᵢ, you simply go to the corresponding row in the table and find your new color RⱼGⱼBⱼ. Each dot in the video is an RGB values (each axis goes from 0.0 to 1.0) and the color of each dot is the output color RⱼGⱼBⱼ.
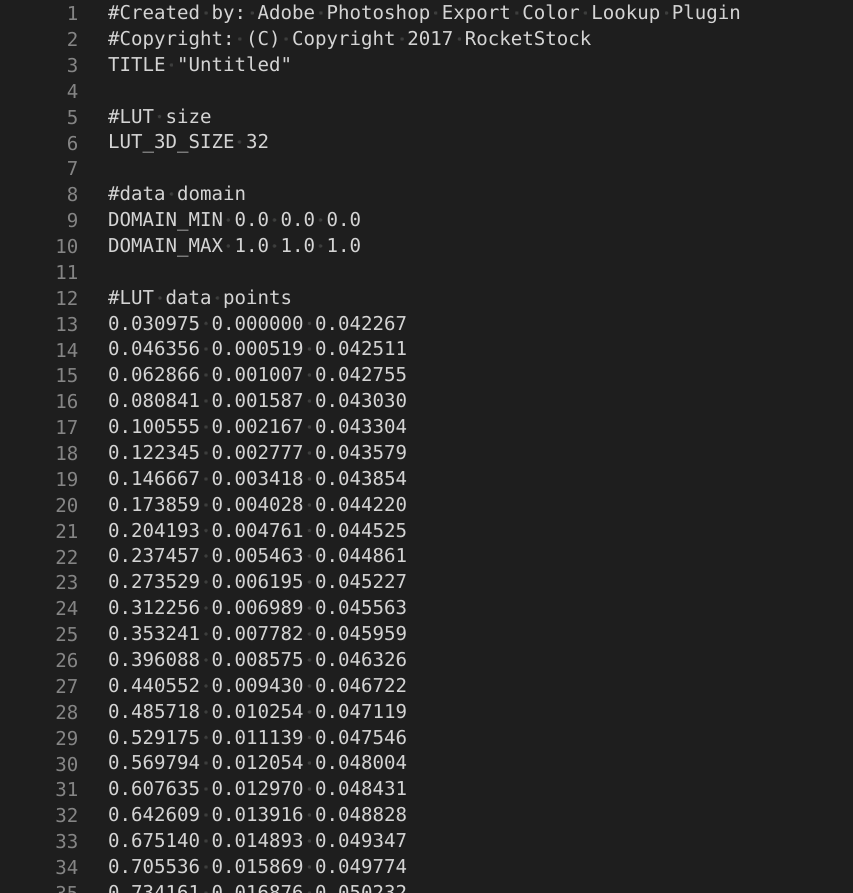
The contents of “Chemical 168.LUT”. It goes on for quite a few lines…
This simplified description glosses over a few details… the main one being that even in 8-bit depth, it’s not practical or useful to include all 8×8×8=16,777,216 possible table rows. If we try looking up a color that’s in between our data points, we need to interpolate between the nearest points. In fact, the cube animation above includes only a subset of the LUT data, and the LUT itself only has 32 points per color axis (about 37k rows).
TL;DR: A Ricoh Theta S can be had for under $60 on eBay. Combined with pfstools, you can easily capture HDRI environment maps and merge them into OpenEXR images.
The Ricoh Theta S is Ricoh’s cheapest 360-degree camera that has automatic bracketing functionality. I bought mine for about $60 on eBay second-hand. The image quality certainly isn’t as good as the flagship Ricoh Theta Z1 ($1,050) but it does the job.
Honestly, I haven’t seen the camera in any color other than black or white.
The automatic bracketing is easy to set up in the app and when run will take each shot in sequence with a few seconds of thinking in between.
The Argus C44 was not a particularly fancy camera. First sold in 1956, it was the latest and greatest (and last) in a line of Argus rangefinders. Most people who know the name Argus know it for the Argus C3, a boxy “everyman’s” camera, but consider that the very next year, Nikon released the famous Nikon F. Nobody would choose to find an Argus at a garage sale over a Nikon F. I was never given the choice.
Anyways, I’m writing this so that at least one person on the Internet will have said positive things about the Argus C44.
The Argus C44’s metal construction feels weighty in my hands. It comes with an attractive set of three lenses (tele, normal, and wide) in individual leather cases. It includes a small viewfinder attachment that sits in the flash shoe and simulates each lens’ field of view. It doesn’t have a light meter but does come with a faint whiff of cigarette smoke (or at least mine did, anyways).
Many people have complained about the infuriating lens mount, but that’s OK—just use the 50mm f/2.8 and keep the other lenses as display pieces. More than sixty years later, it holds up pretty well. Legend holds that it was one of the first camera lenses ever designed with the help of an electronic computer, University of Michigan’s MIDAC. Considering those were the days of vacuum tubes and magnetic-drum memory, that’s a pretty impressive selling point.
The focus ring on my camera is quite difficult to turn, probably due to corrosion or cigarette tar. And looking through the rangefinder only gives an approximate confirmation of focus. So the rough procedure for taking the above photo was:
Right this minute, you can open up Krita and start a new document in linear ACEScg with either 16fp or 32fp encoding. And it works! You can open floating-point OpenEXR files or use the color picker to choose colors like RGB[3.5, 3.0, 1.5] where normally you would be limited to 0.0–1.0. You can paint in a sun with a value of 60.0 if you want, or erase the sun, or whatever! Mostly!
There are still plenty of parts in Krita that do not understand color values above 1.0. For example, I absolutely need to be able to adjust my view “exposure” when working in HDR. Krita has a LUT Management dockable which theoretically uses OCIO to be able to choose a look, exposure, etc. but at least on my recent master build doesn’t seem to do anything. Adding a Slope/Offset/Power filter layer works in a pinch, but unfortunately makes the color picker useless.
This Car Talk episode is a re-run (or some kind of cobbled-together edit) of an older episode, probably from the 1990s. Jef Raskin was probably fairly well known by the time the original episode aired, although I couldn’t find any mention of this connection between him and Car Talk on the Web. And I suppose it’s entirely possible that there was a Jeff Rasken also living in Pacifica at the time, but it seems rather unlikely.
This is old thing I made that I never wrote about here: a thumbnailer for Procreate files. Procreate is a popular iPad drawing and painting app that has its own native *.procreate file format. Most people probably never have to think about this since you can’t access files directly on an iPad and PSD is probably more commonly used for interchange, but it’s pretty straightforward to create thumbnails for Procreate files.
The Procreate files themselves are zip archives and contain a preview image. The thumbnailer just needs to extract the image. Instructions for installing it are in the README file in the linked repo.