TL;DR: It’s easy to write an application launcher fit for your exact needs. You can take my hacky code on Github as a starting point.
The application launcher (Alt+F2 or Meta+R) is the program I run the most on my desktop because it’s the entry point for most everything else I want to run. A while back, I switched from XFCE to KDE too see what things were like having not used KDE since pre-Plasma. I was shocked by the latency in nearly everything: lag to launch system settings, lag to launch even the application launcher (krunner)! Having to wait 400ms after hitting Meta+R before I can start typing is inexcusable for something that should be very simple. I don’t need a fancy start menu that lists my favorite programs. I don’t need it to search over the contents of my files. There are really only a few things that I need it to do:
- Launch a program by name or path
- Open a directory
- Do basic arithmetic
- Do basic unit conversions
Your list of necessary launcher tasks is probably different! I looked around a bit and didn’t find something that had this exact feature set, although some certainly could do everything on this list and a lot more. Krunner, for example, has a plug-in system to do things like dictionary lookups, stock price lookup, etc.
Was krunner slow because, in the spirit of KDE, has lots of settings and extensibility? I decided to try writing my own.
My first attempt was to use PyQt5:
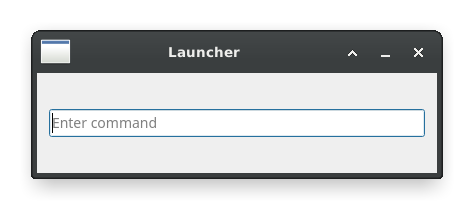
Very simple, import PyQt5 and display a window with a text input. About 45 lines of code total. Yet, it still took approximately 150ms to start (as measured from the top of the script until the end of the GUI’s __init__ function). My computer is not slow – this should launch much faster than that, especially on subsequent runs when any code is cached in memory.
Was it because of some costly Python initialization or something? Using some GPT-4o help, I rewrote this Python program in C++ with Qt. Surprisingly, the C++ version was no faster, clocking in at around 140ms. So Qt itself seemed to be the culprit here.
After some back and forth with ChatGPT, it suggested writing the launcher to use X11 calls directly. While doing this would work around needing a heavy UI toolkit, there are unfortunately some downsides. I won’t get any kind of text editing or interactive features – any text I want to display needs to be drawn by my code and there is no built-in support for anything like keyboard shortcuts, text selection, i18n, nice fonts, etc.
Still, why not try it? I’ve never written code for X11, so I asked the AI for some starter code to hit X11 directly and hacked on it a bit:
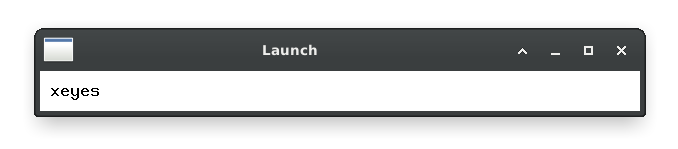
It’s extremely barebones, with not even a blinking text cursor, but the speed is undeniable: 1-2ms to launch. Anything reacting in under 70ms appears to be instantaneous to most users, and this thing basically appears as soon as my keyboard key bottoms out.
On top of this, I added a bunch of code to do simple arithmetic and unit conversion (via units).
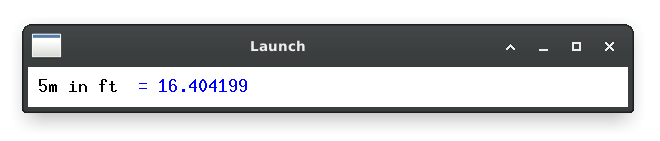
It must be more memory efficient as well, but by how much? gnome-system-monitor says it takes 324 KiB of memory, and the binary itself is about 101 KB. For comparison, krunner sits at about 33 MiB when it’s in the background (although some of that is probably shared KDE libs). My launcher doesn’t need to be backgrounded because there’s no noticeable first-launch penalty.
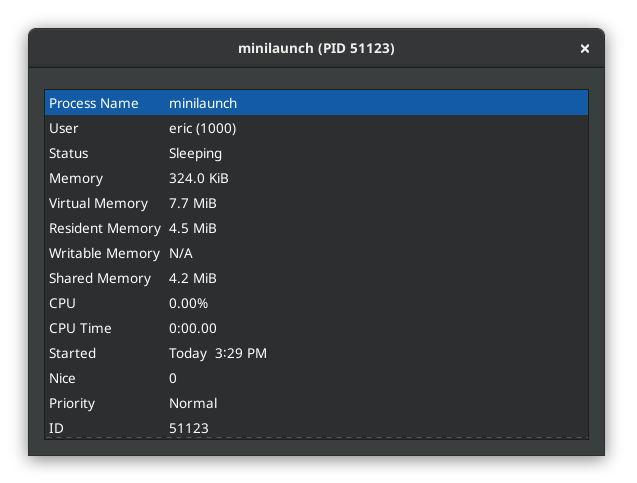
To be clear, the memory usage is not a concern on a machine with 64 GB of RAM, but you can’t spend your way around laggy software. Unless you write code with latency in mind, it’s easy to add in a few dozen ms of time here and there until you end up with an unpleasant user experience that turns users away.
minilaunch code on Github: https://github.com/erjiang/minilaunch